




【NEUTRINO】ver.0.200βがリリースされ、今までオンライン版でしか試せなかったNSFがローカルPCで試せるようになったので、従来のWORLDとの比較をやってみました。
国立情報学研究所が開発した高品質な音声を高速に合成する手法であるニューラル・ソースフィルター・モデル(以下、NSF法)・・・だそうです。
https://www.nii.ac.jp/news/release/2018/1225.html
NIIのサイトを読んでも正直分かりませんが、WORLDと比べてワンランク上の肉声に近い音声が高速に生成できるとのことなので期待は高まります。
今までもオンラインでGoogleのColabなどを使ってNSF合成することはできたのですが、今回のバージョンアップで限定的にオフラインでもNSF合成ができるようになったので早速試してみます。
ローカルでNSF合成を行うにはWindows環境でNVIDIA製のGPUが必要なようです。
ディープラーニングの処理などにNVIDIA製GPUのCUDAが利用されることが多いためだそうです。
β版ということもあってか、Googleドライブ経由での配布になっています。
サンプル1を出力してみると以下の2種類のWAVが出力されます。
_synというのが従来通りのWORLD版の出力で_nsfというのがNSF版の出力のようです。
聴いてみるとWORLD版は正常に出力されていますが、NSF版のほうは無音で出力されています。
エラーで止まったりしていないのでまず、環境を疑ってみます。
私の環境は・・・
SHACHIさんのTwitterによるとGPUメモリが2GBだと動作しない可能性があるとのことですが、4GBなので一応スペックは満たしています。
念のため、GPUのドライバーを最新の445.75というやつにアップデートしておきます。
・・・が、結果は同じく無音で出力されます。
むむむ~
分からないのでログを出力してみると、どうもNSFで変換するところでコケているみたいです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Linguistic feature (duration) : 2 [msec] Linguistic feature (acoustic) : 151 [msec] Separate feature : 157 [msec] Synthesis (NSF) : 202 [msec] Write wav : 609 [msec] Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Finish : 648 [msec] Generation rate : 66.6667 [gen/sec] |
なんかWAVファイルが見つからない的なエラーが出てるけど最終的なWAVファイルは無音で出力された、という状態だったみたいです。
パスが通ってないみたいなことなのかな~と推定して、ProgramFilesの直下に置いていたアプリのフォルダをダメ元でCドライブの直下に移動してみます。
出力してみるとNSFのほうも音声が出力されていて正常に動いたみたいです。
ヨカッタ~。
まず、NSF版の容量がWORLD版に比べて半分なので失敗したのかと思ったのですがエラーではなく仕様みたいです。
出力周波数が48khzの半分の24khzなので容量も半分とういうことです。
聴いた感じでは肉声に近いというよりも一部の発声で滑舌が良くなったような印象を受けます。
特にラリルレロとか、サシスセソが良くなった気がしますが高音域ではWORLDのほうがキレイに出てる感じだと思います。
実は今回初めて謡子のライブラリも試してみたのですが、第1印象としては「何を歌わせても阿佐ヶ谷姉妹みたいになっちゃう」と思いました(笑)
ただ、適度にきれいなビブラートが掛かったりして面白いのでバックでコーラスさせるとかで活用できるんじゃないかな~と思います。
NSF版はきりたんよりも高音域でのかすれが強い感じで、動画を見てもらえれば分かりますがF#4のあたりから苦しそうです。
PitchShiftやFormantShiftが無効になっているため、WORLD版きりたんの「高い声ほど強く歌う」特性を生かした、いわゆるキーを下げてピッチを上げることで「高音域を弱く歌わせる」とかキーを上げてピッチを下げることで「低音域を強く歌わせる」など、バリエーションが作れないということになります。
あとNSFは高音域の”かすれ”なんかはブレスを適切に入れても起きるときは起きるみたいなので、高音域を連続で歌わせるみたいなアレンジは避けたほうが良いのかもしれません。
オリジナル曲であればアレンジで何とかすれば良いと思うのですが、カバー曲だと難しいんじゃないでしょうか。
しかし、 WORLDよりも滑舌が良くなった気がするので使いどころはあるんじゃないかと思います。
CubaseのスコアエディタではNEUTRINO推奨のブレス記号「, (コンマ) 」が記入できません。
そこで・・・
MusicXMLに直接ブレスマークを書き込んで【AIきりたん】にブレスをしてもらおうと思います。
なお、この記事もあくまでMuseScoreを使わずにCubaseだけで【AIきりたん】を歌わせることを目的としてます。
・過去記事
MuseScoreを使わずにCubaseだけで【AIきりたん】を歌わせる方法
FormantShiftを変えて【AIきりたん】の声質を試してみた
まず、やってみたのはSample1のMusicXMLをCubaseのスコアエディタにインポートしてみることでした。
・・・が、ブレス記号の 「, (コンマ) 」 が表示されていません。
この時点でかなり期待薄ですが続けます。
次にCubaseのヘルプを検索してみたのですが、ブレス記号に関するワードがヒットしませんでした。
ならばということで、同じメーカーのSteinberg Doricoという楽譜作成ソフトのヘルプを見てみると、ブレス記号の種類で「V( アップボウ )」でもブレスの替わりになるみたいなことが記載されています。
調べてみるとCubaseのスコアエディタにも 「V( アップボウ )」 と思しき記号があるのでこんな感じで記入してみます。
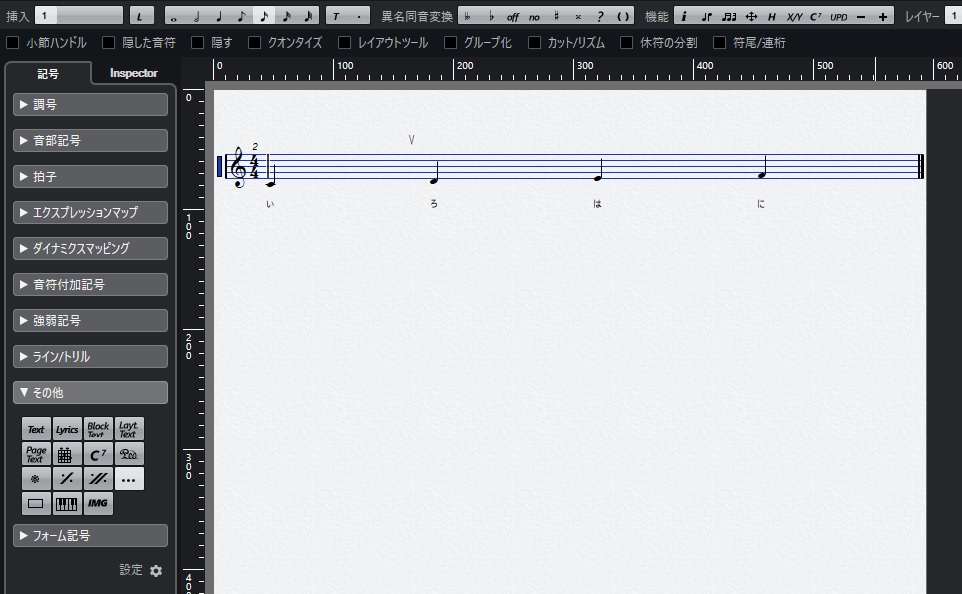
結果から言うと、CubaseのスコアエディタからMusicXMLに書き出した時点で 「V( アップボウ )」 が反映されていませんでした。
おそらく印刷用のフォントとして記入はできるけど【NEUTRINO】で認識できる楽譜データには変換されないのではないかと思います。
ということで、スコアエディタでブレス記号を入れるのは断念して気持ちを入れ替えていきます。
まずはブレスをどんな風に書くのか MusicXMLの 仕様から調べてみます。
すると、こんな文法で書けば良いっぽいことが分かります。
|
1 2 3 4 5 |
<notations> <articulations> <breath-mark default-x="41" default-y="11" placement="above"/> </articulations> </notations> |
次にSample1のMusicXMLをメモ帳で開いて「breath」という文言を検索してみます。
すると、こんな感じでヒットしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<note default-x="99.43" default-y="-15.00"> <pitch> <step>C</step> <octave>5</octave> </pitch> <duration>2</duration> <voice>1</voice> <type>quarter</type> <stem>down</stem> <notations> <articulations> <breath-mark/> </articulations> </notations> <lyric number="1" default-x="6.58" default-y="-53.60" relative-y="-30.00"> <syllabic>single</syllabic> <text>た</text> </lyric> </note> |
分かりにくいですが、要は<note><note/>という要素の中に先ほどの文法で<breath-mark/>を入れてあげれば良いようです。
ということで早速実践してみます。
以下の2点に気を付けながらCubaseで作曲していきましょう。
【AIきりたん】はブレスを入れないで長いフレーズを歌わせると破綻しやすいらしいので少なくとも4小節に1回ぐらいは入れると良いみたいです。
で、出来上がったのがこの曲です。
00:31あたりでブレスしているので聴いてみてください。
動画(歌詞入り)もよろしかったらご覧ください。
メインヴォーカルにコーラスが掛かったような感じがすると思うのですが、実はエフェクトはリバーブとディレイの空間系しか掛かってません。
どうやったかというと・・・
まずは、メインヴォーカルを以下の設定で普通に書き出します。
|
1 2 3 |
: WORLD.exe set PitchShift=1.0 set FormantShift=1.0 |
次に、同じフレーズのキーをCubase側で-12して Run.batのPitchShiftを+12(2.0)で書き出します。
所謂「キー変、ピッチ変」で少し弱く歌ったバージョンを作るイメージです。
|
1 2 3 |
: WORLD.exe set PitchShift=2.0 set FormantShift=1.0 |
書き出したWAVをCubase上で並べただけでボリュームすらいじってないのですが「ダブリング」みたいな効果が得られます。
センの細かった【AIきりたん】の声が少~しだけ太くなってイイ感じになるのでオススメです。
ちなみに【NEUTRINO】で書き出した歌声はMelodyne的なピッチ補正ツールを使用しないで【AIきりたん】の素のままで作成してます。
【NEUTRINO】には【AIきりたん】の声質を「子供っぽく」したり「大人っぽく」したりできる機能が備わっているので、1曲作るついでに声質のテストをしてみました。
ちなみにこの曲もMuseScoreを使わずにCubaseだけで完結することをテーマにしています。
MuseScoreを使わずにCubaseだけで【AIきりたん】を歌わせる方法は←コチラへどうぞ。
【NEUTRINO】のRun.batをメモ帳で開くといくつか自分で設定できる項目があるのですが、今回は声質を変えることのできるFormantShiftの値を変えていきたいと思います。
|
1 2 3 |
: WORLD.exe set PitchShift=1.0 set FormantShift=1.0 |
Readmeでは「上げると子供っぽく、下げると大人っぽく」なると記述されており、「0.85-1.15辺りがお勧めです」という注記があるので、今回は・・・
という3種類の声質を作ってみます。
set FormantShift=1.15 で子供っぽい声になるのは確認できました。
しかし、C4以上の高いキーになってくると正しく発声しない現象が起きてしまいました。
くろ州さんのまとめによると、直前に休符があると起きやすいそうで、対策としては以下の2つがあるそうです。
ブレスを入れるのが1番手っ取り早そうなのでやってみる・・・
と、思ったら落とし穴が!
Cubaseのスコアエディタには「’」を記入することができないようです。
調べてみたんですがMusicXMLで認識される<breath-mark>を入れること自体ができない感じなので、あとで調査することにしてブレスをいれるのはいったんパスします。
ダミーノートを入れて後で消すのはあまりスマートじゃないので最後の切り札として取っておくことにします。
またくろ州さんのまとめを見ると「キー変更+ピッチ変更」でうまく歌うところを探すというテクニックがあるようです。
今回は高い声が出ていないので「キーを下げてピッチを上げる」ということをすれば解決するのではないかと推測してみました。
これで書き出してみると見事!無声化していた問題が解消されました。
【AIきりたん】は「低いキーは弱く、高いキーは強く」歌う傾向があるので 「キー変更+ピッチ変更」 でうまく歌うまで調整するのが良いそうです。
今回はコーラスで高い声なので、メインヴォーカルより目立たないように「キーを下げて弱くしながらもピッチは上げて高音を歌ってもらう」という方向にしてみました。
曲の後半のサビで実践しているので聴いてみてください。
いやぁ~、くろ州さんのような先駆者がいて大変助かりました。
ピッチ変更早見表まで掲載してくれててマジ感謝です!
話題の【AIきりたん】ですが、私の愛用DAWのCubaseでもMusicXMLが書き出せるということで早速試してみました。
・・・が、結果的に言うと、そのままではNEUTRINOに読み込むことができなかったので備忘録的に記事と動画を作成しました。
あくまで私のやり方ではありますが、ご参考になればと思います。
※SleepFreaksさんの記事参照
https://sleepfreaks-dtm.com/dtm-materials/neutrino/
NEUTRINOとしてはMuseScoreが推奨されているのですが、ノーテーションソフトはあまり慣れていないので、普通にCubaseのピアノロールで曲を作っていきます。
【AIきりたん】に歌わせたいパートは単音で独立したトラックに作ります。
デュレーション(音の長さ)は反映されますが、ベロシティ(鍵盤をたたく強さ)は反映されないみたいなので細かく考えずに作っていきましょう。
【AIきりたん】に歌わせたいパートのトラックを選択してスコアエディタを開きます。
左側の記号ペインから「その他」を選択し、「Lyrics」ボタンをクリックすると歌詞の入力モードになります。
音符の下辺りをクリックすると文字入力ができるので日本語で打ち込んでください。
ちなみに、私は何も歌詞が思いつかなかったので「ららら~」と「トゥトゥトゥ~」でお茶を濁してますw
すべての音符に歌詞を入力し終えたら、スコアエディタを開いたまま「ファイルメニュー」→「書き出し」→「MusicXML」を選択。
適当なファイル名を付けて保存します。
これでCubaseからMusicXMLを書き出すことができました。
できた.xmlをNEUTRINOに読み込ませようとするとエラーが出てしまいます。
ということで、サンプルで付いているMusicXMLを参考にしながら必要最小限の手直ししていきたいと思います。
サンプルをメモ帳で開くと・・・
|
1 |
<?xml version="1.0" encoding="UTF-8"?> |
一方、Cubaseで書き出したモノをメモ帳で開くと・・・
|
1 |
<?xml version="1.0" encoding="UTF-16" standalone="no"?> |
まず、行頭の定義からして違います。
UTFの形式が違うので「16」から「8」に書き換えます。
次に、Cubaseで書き出したモノにはテンポの記述がないので<attributes>というセクションに<sound tempo=”XXX”/>を追加します。
※XXXのところにテンポの数値を記入
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<attributes> <divisions>480</divisions> <key> <fifths>0</fifths> </key> <time> <beats>4</beats> <beat-type>4</beat-type> </time> <clef number="1"> <sign>G</sign> <line>2</line> </clef> <sound tempo="130"/> </attributes> |
これで必要最小限の手直しは済んだと思うので「名前を付けて保存(A)」で保存します。
この時、保存形式を「UTF-8」にするのを忘れないように!
手直しした.xmlをNEUTRINOフォルダのなかの「musicxml」フォルダにコピーします。
サンプルの拡張子が.musicxmlになっているので、一応、拡張子も合わせて変更しておきます。
「使えなくなるかも…」みたいな警告が出ますが、かまわず「はい」を選択してください。
あとはNEUTRINOの手順通り、.batの「set BASENAME=」以降を自分の作ったMusicXMLのファイル名にしてコマンドラインでバッチを走らせてください。
エラーが出なければ成功です!
NEUTRINOフォルダのなかの「output」フォルダに.wavが書き出されているのを確認しましょう。
Cubaseに戻ってきて「ファイル」→「読み込み」 → 「オーディオファイル」で NEUTRINOフォルダのなかの「output」フォルダから書き出された.wavを読み込みます。
元のメロディのトラックをMuteして聞いてみましょう。
ベタ打ちにも関わらず(歌詞もららら~なのに)かなり自然に発生してますね!
本来はNEUTRINO推奨のMuseScoreを使うのが良いとは思うのですが、DAWを行き来したりするのはメンドくさいので「Cubaseだけで完結するやり方ないかな~」と思ってテストしてみました。
しかし、こんな素晴らしいソフトがフリーウェアで公開されているなんて驚きです。
しかも【AIきりたん】は非商用であればクリエイターがYoutubeなどへの投稿もできるのでますます広がりそうな気がします。
わたしも何か1曲作ってみようかな!
・AIきりたんガイドライン
https://zunko.jp/guideline.html
・AIきりたんデータベースガイドライン
https://zunko.jp/kiridev/login.php
・NEUTRINO
https://n3utrino.work/
さてさて、「源平討魔伝」にはビッグモードと横スクロールモード、4方向スクロールモード、それぞれにメインBGMが設定されているのですが、今回はミドルテンポで重厚な感じのビッグモードのBGMを耳コピしていきましょう。
まず、原曲を聞いていきます。
ベースがゴロゴロした音色のFMスラップベースが特徴的なので、DEXEDのプリセットを探していきます。
似た音でも20パターン以上あるので探すのは大変なのですが「Bass」というキーワードで1音ずつ聞いていくことにしましょう。
CART(たぶんカートリッジの略)というボタンを押してカートリッジのプリセットを見ていくと、Yamaha_DX7_syx2の中にBass.syxというのが並んでいるのでこの辺で探します。
各.syxには32個のプリセット音色が内蔵されているようです。
これらを1音、1音確かめながら探していくといくつか似ている音色の中からBass03.syxというのの中のBrainacus0という音色が良さそうな感じなので決定します。
こんな感じで、音を探していくスタイルでやって行けそうです。
『トレジャー発掘!Diggers』
【iOS】
【Android】
はい!恒例のVSTでのシミュレート音源探しから始めてみましょうか。
メジャーどこではNativeinstruments FM8 とか、Imageline Sytrus あたりかな。
フリーVSTiで評判が高いのがDEXED とかVOPM ですね。
特にVOPMは80年代のアーケード基盤やX68000で採用されていたYM2151というチップをシミュレートしていて雰囲気的にはコレがよさそうな感じがするのですが、※1随分前に開発終了していて64ビット化されていないのでアウトです。
メジャーどこはもちろん申し分ないのですが、DEXEDが評価が高いうえに64ビット化もされていて「フリーで使い物になるならこっちでも良いよね」と思い、DEXEDをチョイスしてみたいと思います。
DEXEDはYAMAHAのDX7をシミュレートしたVSTiで、大量のプリセット音色が※2カートリッジファイルとして配布されていて、しかもリアルのDX7ユーザーであればキーボード側で作った音色をMIDIのSysEXとして送ることでDEXEDに取り込むこともできるという優れものです。
今回の耳コピではFM音源の音色を1から作ると、それだけで迷宮に入ってしまいそうなので、DEXEDの大量のプリセットから探して使う作戦で行こうと思います。
次回から「源平討魔伝」のビッグモードの曲を耳コピしていくことにしましょう。
※1PPSE さんという有志による64ビット化もされているようですが今回はパスしました。
※2DX7では追加音色をROMカートリッジで販売していてたくさん持っているとちょっと自慢だったのです。
『トレジャー発掘!Diggers』
【iOS】
【Android】
PSG音源(ファミコン音源)、波形メモリ音源、ときてレトロゲームのサウンドを語るうえで欠かせないのが「FM音源」です。
「FM音源」のFMとは「FrequencyModulation(フリケンシー・モジュレーション)」の略で、日本語で言うと「周波数変調」となります。
オペレータと呼ばれる基本波形に周波数変調をかけることで、非常に複雑な波形を生み出すことができる方式のことで、例えば基本的なサイン波に周波数変調で複雑な歪みを与えることで元の波形にはなかったような波形を生み出すことが可能になります。
さらに複数のオペレータをいろいろなパターンで組み合わせて音色を作ることができるため、当時は※1原理的にはどんな音でも演算で作り出すことができると言われていました。
音の特徴としては、金属的でキラキラした音色を奏でることができるのでアナログシンセサイザーとはまた違った意味で電子音楽で重宝されていました。
80年代~90年代のアーケードゲームといえば「FM音源」というくらい数多くのタイトルに採用されており、「トレジャー発掘!Diggers」でいえば以下のタイトルがFM音源ものということになります。
・妖怪道中記
・源平討魔伝
・ワンダーモモ
・シティコネクション
・妖精物語ロッドランド
・カルノフ
・トリオザパンチ
・空牙
・ウルフファング
・ダークシール
次回からナムコの「源平討魔伝」を例にとってお話していきましょう。
※1実際にはFM音源の音色づくりは非常に難解で狙った音を作るのが難しく、どんな音でも作れるというわけにはいかなかった
『トレジャー発掘!Diggers』
【iOS】
【Android】
さぁ、耳コピをどんどん進めていきます。
メロディ、カウンターメロディ、ベースの3パートしかないのでサクサク進みます。
あらかた出来上がったところで聞いてみます。
う~~~ん。
なぁ~んか、レトロっぽさが出てないのです。
Retrologueも、レトロと銘打っている割にはステレオの分離もいいし、上から下までレンジが広くて、良い意味で現代の音楽でも使えるシンセなので、原曲が持っている塊感が出ないのではないでしょうか。
各トラックでEQの設定を変えて上下の帯域を絞るみたいなこともしてみたのですが、どうもレゾリューションが高すぎるのが原因でないかと当たりをつけてみます。
ナムコのマッピーで採用されていた波形メモリ音源はC30というものらしいのですが、スペック的には、4ビット、32サンプル、最大発音数8または16。ステレオまたはモノラルということなので、ここはまた大胆に読み替えをしてみます。
上下の帯域を絞ってレゾリューションを下げるってことは、Hi-FiからLo-Fiにするわけですから、全体にLo-Fiエフェクトかけたらいいんでないか?ということです。
Cubase標準エフェクトのbitCrussherでパラメータをいじってみます。
Modeというセクションでキャラクターを決めて、SampleDividerというツマミで歪み具合を調節、Depthというツマミでビットレゾリューションを0~24の間で決めます。
ModeはⅢで比較的強めにかかるキャラクターに設定。
SampleDividerはかけすぎると壊れた無線みたいな音になってしまうので1に設定。
DepthはC30のスペックが4ビットなので4にしたらすこしノイジーすぎるので8にしてみます。
このような設定で再生してみます。
まぁ、シミュレート音源ではないわりに雰囲気だけは似たのではないかと思います。
「マッピー」のBGMはゲーム本編の「アニマルワールド」で聞けるので、似てるか似てないか。
原曲を思い出しながら聞いてみて下さいまし。
ということで波形メモリ音源編は今回で終了。
次回からFM音源編です!
『トレジャー発掘!Diggers』
【iOS】
【Android】
メロディパートの音色はできたので、次はカウンターメロディを奏でているパートの音色の作成をしていきましょう。
ファミコン版の「マッピー」では鳴っていないのですが、アーケード版では波形メモリ音源独特の音色で鳴っていて、耳コピ再現する場合は特に重要なパートです。
さっそく原曲を聞いてみましょう。
ベル系のような、エレピ系のような金属的なアタックと涼やかなサスティンで構成された音色ですね。
PSG音源では絶対出ない感じの波形メモリ音源の特徴的な音です。
Retrologueで1から再現するのが難しそうなので、ちょっと考え方を変えて、Retrologueのプリセット音色の中から比較的似ているものを探してそこからエディットすることにしてみます。
Retrologueのプリセットの中で比較的軽めのエレピ音色が良いと思うので「FM E-Piano」という音色をロードしてみます。
まずはエフェクトが掛かっていてゴージャスな感じが邪魔なので、コーラス、ディレイ、リバーブをOffにして素の音にします。
さらにローの音が出すぎなのでSUBセクションのボリュームを絞ります。
この音色でキーボードを弾くと、ベロシティ110あたりがちょうど似ている音になるので、全体的にベロシティ110に設定してみます。
とりあえず、音色はこれでFIXして曲全体の耳コピを進めていきます。
『トレジャー発掘!Diggers』
【iOS】
【Android】
それでは「マッピー」原曲を聞いてみましょう。
非常にリリースの短い歯切れのよい、バンジョーっぽい感じの音でメロディを奏でています。
ネズミの保安官?みたいなので、ちょっとアメリカンなテイストがするカントリーウエスタンな雰囲気を意識しているのでしょうかネ。
Retrologueのオシレータを適当に切り替えながら音色作成を開始していきます。
バンジョーっぽい少し角がたったような音色にしたいので、ノコギリ波を選択してみますが、いまいちです。
オシレータは3つまで重ねられるのでもう一つノコギリ波を重ねて、オクターブを下げてみます。
う~ん・・・分厚くはなったけどちがうなぁ。
こういう時は原曲に立ち返るのが鉄則です。
よ~く聞いてみると、歯切れは良いけど少し高音の角がつぶれて独特の響きがあるので、ここを踏まえないといけないのかな?・・・ということで、方針転換。
今度はオシレータは矩形波にして、3つ重ねて、ついでに1オクターブ上と下に振ってあげます。
さらにSUBオシレータもONにして矩形波を重ねることで、4つの音が倍音っぽく重なった分厚い矩形波ができました。
さらにさらに、バンジョーの金属っぽい感じを出したいので、オシレータMIXセクションでリングモジュレータを50%ぐらいかけてあげて、4つそれぞれのオシレータのボリュームを微調整し、アンプセクションで、アタック最速・ディケイそこそこ・サスティン0・リリース短め、に設定してあげます。
まぁまぁ、そっくりそのままではないけど、雰囲気は出てる音色ができたのでメインのメロディはこれで行くことにしましょう。
『トレジャー発掘!Diggers』
【iOS】
【Android】