




【NEUTRINO】ver.0.200βがリリースされ、今までオンライン版でしか試せなかったNSFがローカルPCで試せるようになったので、従来のWORLDとの比較をやってみました。
国立情報学研究所が開発した高品質な音声を高速に合成する手法であるニューラル・ソースフィルター・モデル(以下、NSF法)・・・だそうです。
https://www.nii.ac.jp/news/release/2018/1225.html
NIIのサイトを読んでも正直分かりませんが、WORLDと比べてワンランク上の肉声に近い音声が高速に生成できるとのことなので期待は高まります。
今までもオンラインでGoogleのColabなどを使ってNSF合成することはできたのですが、今回のバージョンアップで限定的にオフラインでもNSF合成ができるようになったので早速試してみます。
ローカルでNSF合成を行うにはWindows環境でNVIDIA製のGPUが必要なようです。
ディープラーニングの処理などにNVIDIA製GPUのCUDAが利用されることが多いためだそうです。
β版ということもあってか、Googleドライブ経由での配布になっています。
サンプル1を出力してみると以下の2種類のWAVが出力されます。
_synというのが従来通りのWORLD版の出力で_nsfというのがNSF版の出力のようです。
聴いてみるとWORLD版は正常に出力されていますが、NSF版のほうは無音で出力されています。
エラーで止まったりしていないのでまず、環境を疑ってみます。
私の環境は・・・
SHACHIさんのTwitterによるとGPUメモリが2GBだと動作しない可能性があるとのことですが、4GBなので一応スペックは満たしています。
念のため、GPUのドライバーを最新の445.75というやつにアップデートしておきます。
・・・が、結果は同じく無音で出力されます。
むむむ~
分からないのでログを出力してみると、どうもNSFで変換するところでコケているみたいです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Linguistic feature (duration) : 2 [msec] Linguistic feature (acoustic) : 151 [msec] Separate feature : 157 [msec] Synthesis (NSF) : 202 [msec] Write wav : 609 [msec] Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Error: input wav file not found. Finish : 648 [msec] Generation rate : 66.6667 [gen/sec] |
なんかWAVファイルが見つからない的なエラーが出てるけど最終的なWAVファイルは無音で出力された、という状態だったみたいです。
パスが通ってないみたいなことなのかな~と推定して、ProgramFilesの直下に置いていたアプリのフォルダをダメ元でCドライブの直下に移動してみます。
出力してみるとNSFのほうも音声が出力されていて正常に動いたみたいです。
ヨカッタ~。
まず、NSF版の容量がWORLD版に比べて半分なので失敗したのかと思ったのですがエラーではなく仕様みたいです。
出力周波数が48khzの半分の24khzなので容量も半分とういうことです。
聴いた感じでは肉声に近いというよりも一部の発声で滑舌が良くなったような印象を受けます。
特にラリルレロとか、サシスセソが良くなった気がしますが高音域ではWORLDのほうがキレイに出てる感じだと思います。
実は今回初めて謡子のライブラリも試してみたのですが、第1印象としては「何を歌わせても阿佐ヶ谷姉妹みたいになっちゃう」と思いました(笑)
ただ、適度にきれいなビブラートが掛かったりして面白いのでバックでコーラスさせるとかで活用できるんじゃないかな~と思います。
NSF版はきりたんよりも高音域でのかすれが強い感じで、動画を見てもらえれば分かりますがF#4のあたりから苦しそうです。
PitchShiftやFormantShiftが無効になっているため、WORLD版きりたんの「高い声ほど強く歌う」特性を生かした、いわゆるキーを下げてピッチを上げることで「高音域を弱く歌わせる」とかキーを上げてピッチを下げることで「低音域を強く歌わせる」など、バリエーションが作れないということになります。
あとNSFは高音域の”かすれ”なんかはブレスを適切に入れても起きるときは起きるみたいなので、高音域を連続で歌わせるみたいなアレンジは避けたほうが良いのかもしれません。
オリジナル曲であればアレンジで何とかすれば良いと思うのですが、カバー曲だと難しいんじゃないでしょうか。
しかし、 WORLDよりも滑舌が良くなった気がするので使いどころはあるんじゃないかと思います。
CubaseのスコアエディタではNEUTRINO推奨のブレス記号「, (コンマ) 」が記入できません。
そこで・・・
MusicXMLに直接ブレスマークを書き込んで【AIきりたん】にブレスをしてもらおうと思います。
なお、この記事もあくまでMuseScoreを使わずにCubaseだけで【AIきりたん】を歌わせることを目的としてます。
・過去記事
MuseScoreを使わずにCubaseだけで【AIきりたん】を歌わせる方法
FormantShiftを変えて【AIきりたん】の声質を試してみた
まず、やってみたのはSample1のMusicXMLをCubaseのスコアエディタにインポートしてみることでした。
・・・が、ブレス記号の 「, (コンマ) 」 が表示されていません。
この時点でかなり期待薄ですが続けます。
次にCubaseのヘルプを検索してみたのですが、ブレス記号に関するワードがヒットしませんでした。
ならばということで、同じメーカーのSteinberg Doricoという楽譜作成ソフトのヘルプを見てみると、ブレス記号の種類で「V( アップボウ )」でもブレスの替わりになるみたいなことが記載されています。
調べてみるとCubaseのスコアエディタにも 「V( アップボウ )」 と思しき記号があるのでこんな感じで記入してみます。
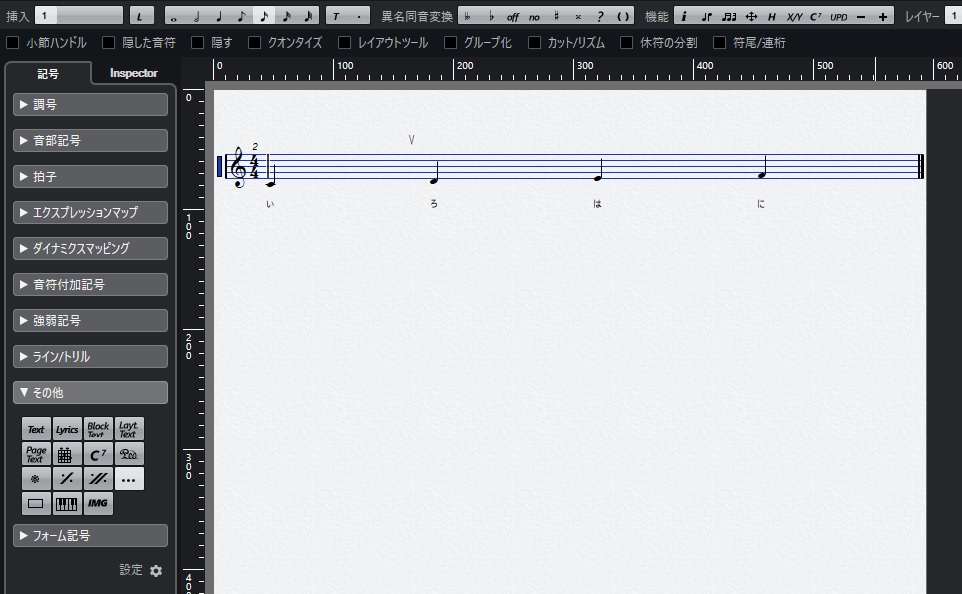
結果から言うと、CubaseのスコアエディタからMusicXMLに書き出した時点で 「V( アップボウ )」 が反映されていませんでした。
おそらく印刷用のフォントとして記入はできるけど【NEUTRINO】で認識できる楽譜データには変換されないのではないかと思います。
ということで、スコアエディタでブレス記号を入れるのは断念して気持ちを入れ替えていきます。
まずはブレスをどんな風に書くのか MusicXMLの 仕様から調べてみます。
すると、こんな文法で書けば良いっぽいことが分かります。
|
1 2 3 4 5 |
<notations> <articulations> <breath-mark default-x="41" default-y="11" placement="above"/> </articulations> </notations> |
次にSample1のMusicXMLをメモ帳で開いて「breath」という文言を検索してみます。
すると、こんな感じでヒットしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<note default-x="99.43" default-y="-15.00"> <pitch> <step>C</step> <octave>5</octave> </pitch> <duration>2</duration> <voice>1</voice> <type>quarter</type> <stem>down</stem> <notations> <articulations> <breath-mark/> </articulations> </notations> <lyric number="1" default-x="6.58" default-y="-53.60" relative-y="-30.00"> <syllabic>single</syllabic> <text>た</text> </lyric> </note> |
分かりにくいですが、要は<note><note/>という要素の中に先ほどの文法で<breath-mark/>を入れてあげれば良いようです。
ということで早速実践してみます。
以下の2点に気を付けながらCubaseで作曲していきましょう。
【AIきりたん】はブレスを入れないで長いフレーズを歌わせると破綻しやすいらしいので少なくとも4小節に1回ぐらいは入れると良いみたいです。
で、出来上がったのがこの曲です。
00:31あたりでブレスしているので聴いてみてください。
動画(歌詞入り)もよろしかったらご覧ください。
メインヴォーカルにコーラスが掛かったような感じがすると思うのですが、実はエフェクトはリバーブとディレイの空間系しか掛かってません。
どうやったかというと・・・
まずは、メインヴォーカルを以下の設定で普通に書き出します。
|
1 2 3 |
: WORLD.exe set PitchShift=1.0 set FormantShift=1.0 |
次に、同じフレーズのキーをCubase側で-12して Run.batのPitchShiftを+12(2.0)で書き出します。
所謂「キー変、ピッチ変」で少し弱く歌ったバージョンを作るイメージです。
|
1 2 3 |
: WORLD.exe set PitchShift=2.0 set FormantShift=1.0 |
書き出したWAVをCubase上で並べただけでボリュームすらいじってないのですが「ダブリング」みたいな効果が得られます。
センの細かった【AIきりたん】の声が少~しだけ太くなってイイ感じになるのでオススメです。
ちなみに【NEUTRINO】で書き出した歌声はMelodyne的なピッチ補正ツールを使用しないで【AIきりたん】の素のままで作成してます。